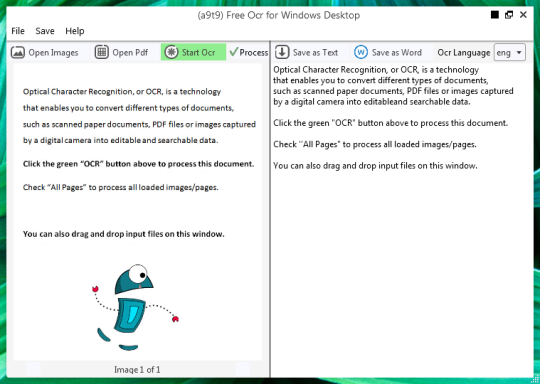
software-ul gratuit OCR pentru a extrage text din imagini și obiecte PDF. O interfață grafică cu utilizatorul (GUI) pentru motorul Tesseract OCR.
Cererea este simplu de instalat și, mai important, libertatea de a folosi, open-source și 100% adware și spyware gratuit.
Puteți deschide un fișier imagine sau PDF. Conținutul fișierului sursă va fi afișată în fereastra din stânga. În cazul în care documentul ca mai mult de o pagină, sau dacă ați deschis documentelor cu pagini multiple, utilizați săgețile din partea de jos pentru a comuta între ele,
Puteți începe OCR făcând clic pe butonul verde OCR, și veți vedea rezultatul în cea de a doua fereastra din dreapta. Textul de ieșire pot fi salvate ca un fișier text sau un document Word.
Din păcate, calitatea de conversie nu este atât de mare. În spatele scenei se foloseste open-source motorul OCR Tesseract. Calitatea variază de la o limbă la alta -. Merge atât de departe și de testare, dacă este suficient pentru nevoile dvs.
Pentru dezvoltatorii de software și avansați: OCR gratuit pentru instrument Windows Desktop este în esență o interfață grafică de utilizator front-end (GUI) pentru motorul Tesseract OCR. Complet codul sursă al este disponibil (licenta GPL).
Motorul OCR a software-ul acceptă următorul limba OCR: engleză, franceză, italiană, germană, spaniolă, portugheză braziliană și olandeză. Incepand cu versiunea 3, acesta poate recunoaște arabă, bulgară, catalană, chineză (simplificată și tradițională), croată, cehă, daneză, olandeză, engleză, germană (standard si script Fraktur), greacă, finlandeză, franceză, ebraică, hindi, maghiară, indoneziană, italiană, japoneză, coreeană, letonă, lituaniană, norvegiană, poloneză, portugheză, română, rusă, sârbă, slovacă (standard si script Fraktur), slovenă, spaniolă, suedeză, tagalog, Tamil, thailandeză, turcă, ucraineană și vietnameză.

Comentariile nu a fost găsit