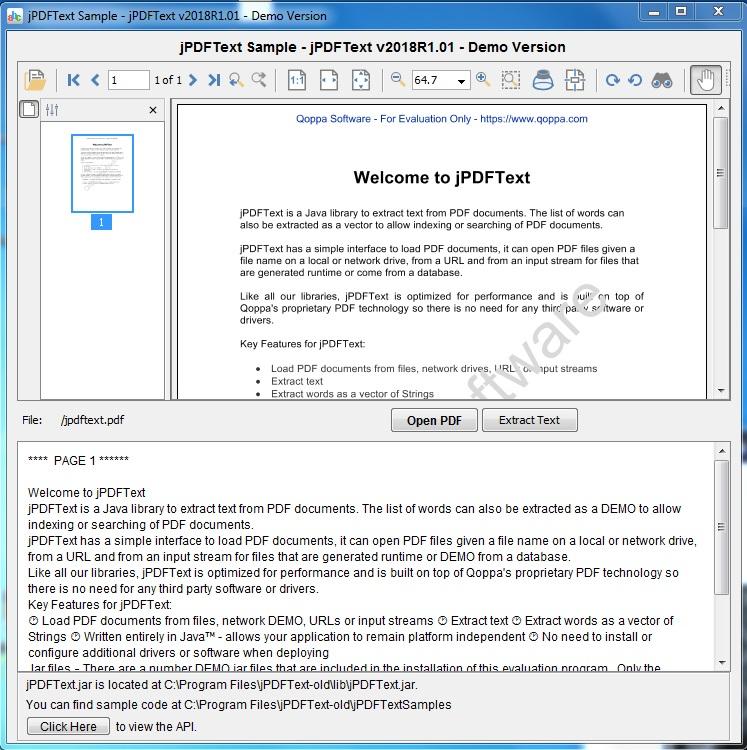
jPDFText este o bibliotecă Java pentru extragerea textului din documente PDF. Cu jPDFText, documentele PDF pot fi procesate pentru a extrage conținutul textual pentru arhivare, stocare, căutare sau indexare. jPDFText este construit pe tehnologia PDF proprietate Qoppas, deci nu trebuie să instalați niciun software sau drivere pentru terțe părți. Deoarece este scris în Java, permite aplicației dvs. să rămână independentă de platformă și să ruleze pe Windows, Linux, Unix (Solaris, HP UX, IBM AIX), Mac OS X și orice altă platformă care suportă mediul de rulare Java. >
Caracteristici principale:
Încărcați documente PDF din fișiere, unități de rețea, adrese URL sau fluxuri de intrare.
Extrageți textul în ordinea de citire logică.
Extrageți cuvintele ca vector de șir.
Funcționează pe Windows, Linux, Unix și Mac OS X (100% Java).
Nu este nevoie să instalați sau să configurați drivere suplimentare sau programe software în timpul implementării.
Testat pe JDK 1.4.2 și mai sus.
Comentariile nu a fost găsit