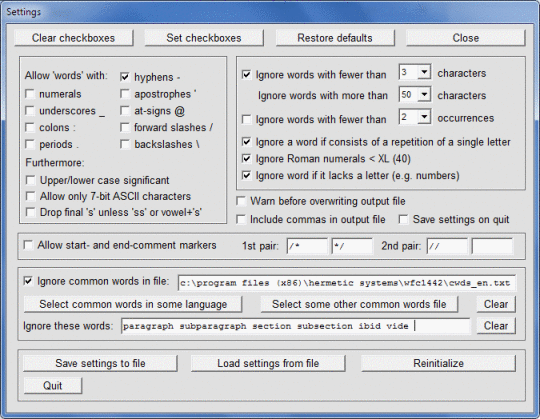
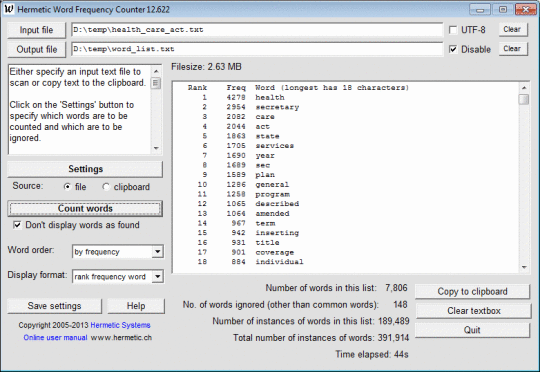
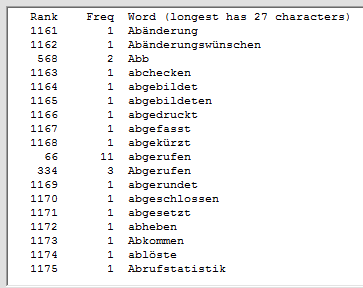
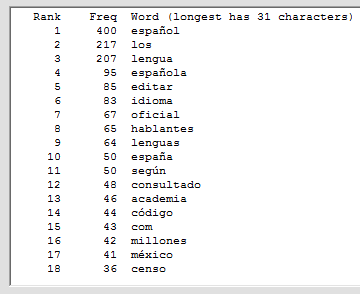
Acest software scanează un fișier docx MS Word sau un fișier text (inclusiv fișiere HTML și XML) cu text codificat prin ANSI sau UTF-8 și numără frecvențele diferitelor cuvinte. Cuvintele care sunt găsite și afișate pot fi ordonate în ordine alfabetică sau în funcție de frecvență. Caracterele care pot apărea în cuvinte pot fi specificate, astfel încât programul poate fi spus să permită sau să interzică cuvinte cu cifre, cratime, apostrofe, sublinieri sau coloane pentru a ignora cuvinte scurte sau care apar rar, pentru a trata literele minuscule semnificative sau nu, și ignorarea cuvintelor (de exemplu, cuvinte comune precum "acest") conținute într-un fișier specificat. Acest software poate fi folosit cu text în alte limbi decât limba engleză, în special cu textul francez, german, italian și spaniol. Limba textului este detectată automat și fișierul corespunzător "cuvinte comune" (cu cuvinte care trebuie ignorate) este opțional încărcat. Rezultatele pot fi scrise într-un fișier de ieșire și apoi pot fi citite în Excel pentru procesare ulterioară.
Ce este nou în această versiune:
Versiunea 19.36: Opțiunea de a converti plural cuvinte pentru singular pentru numărare.
Ce este nou în versiunea 19.26:
Instalare îmbunătățită
în versiunea 18.22:
Îmbunătățirea procesării fișierelor XML.
Ce este nou în versiunea 16.52:
Versiunea 16.52 poate include actualizări nesemnificative, reparații de erori
Ce este nou în versiunea 16.42:
Versiunea 16.42 poate include actualizări, îmbunătățiri sau remedierile de erori nespecificate. > Ce este nou în versiunea 16.22:
Versiunea 16.22 poate include actualizări, îmbunătățiri sau corecții de erori nespecificate.
Ce este nou în versiunea 15.52:
Versiunea 15.52 a rezolvat o eroare în recunoașterea fișierelor text codate UTF-8.
Ce este nou în versiunea 14.42:
Suport adăugat pentru fișiere cu text mixt engleză / chineză.
Limitări :
Procesul de 30 de zile, funcționalitate limitată
Comentariile nu a fost găsit