
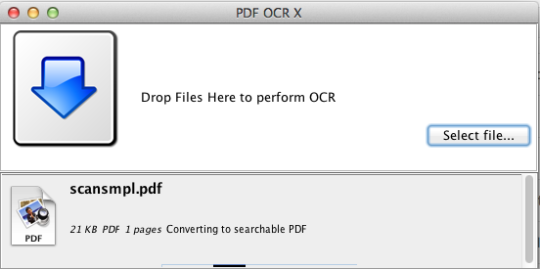
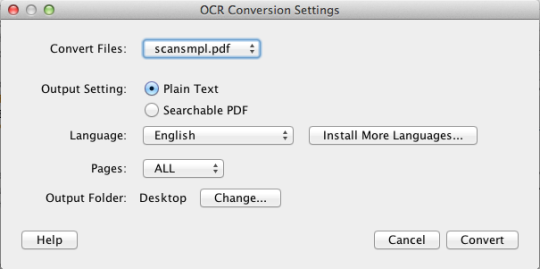
PDF OCR X este un utilitar de drag-and-drop simplu pentru Mac OS X, care convertește PDF-urile și imaginile în documente PDF sau PDF. Utilizează tehnologia OCR avansată (recunoașterea optică a caracterelor) pentru a extrage textul PDF (sau imaginea) chiar dacă textul este conținut într-o imagine. Acest lucru este deosebit de util pentru tratarea PDF-urilor și a imaginilor create printr-o funcție Scan-to-PDF într-un scaner sau copiator foto. Suportă peste 60 de limbi pentru OCR. Motorul OCR se bazează pe Tesseract. Ediția comunitară acceptă PDF-uri cu o singură pagină (sau prima pagină a PDF-urilor cu mai multe pagini). Pentru suport PDF în mai multe pagini, trebuie să faceți upgrade la Enterprise Edition.
Ce este nou în această versiune:
Versiunea 2.1.1 adaugă suport pentru Mojave și îmbunătățește interfața utilizator pe afișajele retinei.
Ce este nou în versiunea 2.0.8:
Problemă fixă cu manipularea unor fișiere PDF cu rotație. >
Limitări :
Ediția comunitară este limitată la PDF-uri și imagini pe o singură pagină.


Comentariile nu a fost găsit